Ubunifu Madness started as a Kaggle entry for the March Machine Learning Mania competition and grew into a full platform: live win probabilities, power rankings, a bracket simulator, an honest accuracy tracker, and a conversational agent that answers questions about teams and matchups. The engineering lesson I keep coming back to is not about the model. It is about discipline at the boundaries: one source of truth for predictions, and an agent that is structurally prevented from inventing facts.
One prediction function, every surface
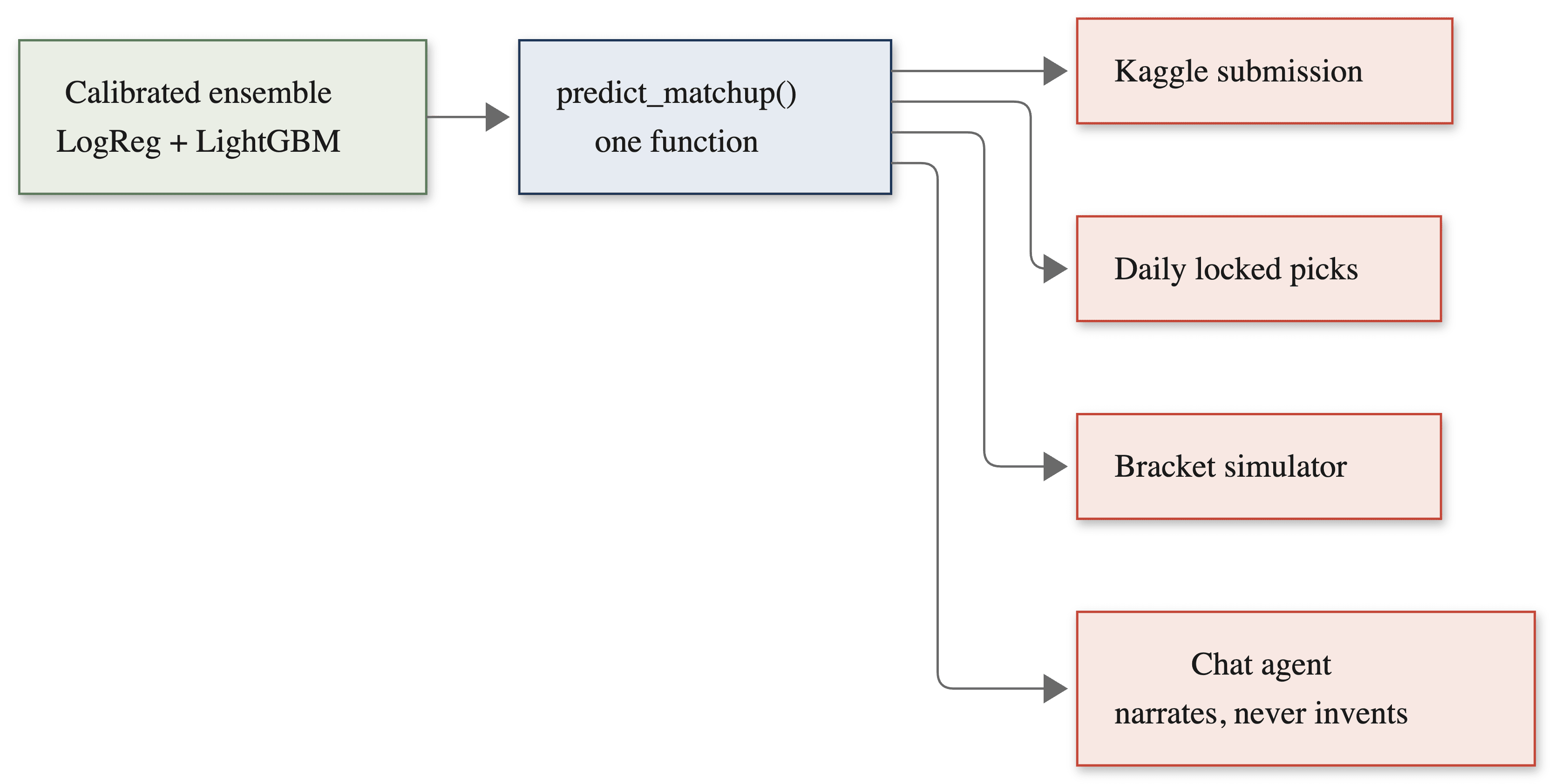
The most important architectural decision was to route every prediction through a single function. The same predict_matchup call serves the Kaggle submission, the locked daily picks, the Monte Carlo bracket simulation, and every answer the chat agent gives about a matchup. There is no second code path where the website and the agent could quietly disagree about who is favored.
This sounds obvious and was not free. It meant the live system had to reconstruct the model's full feature vector from current database state on demand, rather than reading precomputed predictions from a file. The payoff is that there is exactly one number for any matchup, and one place to fix if it is wrong.
The model, and why 2012
The model is an ensemble: a logistic regression and a LightGBM gradient-boosted model, blended with fixed weights, on forty-three engineered features. Every feature is expressed as a difference between the two teams, so the model is symmetric by construction. The features span Elo ratings, tournament seeds, conference strength, Four Factors efficiency, published ranking systems, momentum, strength of schedule, and a few volatility measures I added later, like how often a team plays close games.
I trained on games from 2012 onward only. College basketball before the three-point revolution, the transfer portal, and name-image-likeness is a different sport in ways the model would learn wrongly. Rather than throw away the structure of older games, I trained on all game types (regular season, conference tournaments, the NCAA tournament) and gave the model context flags so it could learn that a neutral-site tournament game behaves differently from a home regular-season one. Recent seasons are weighted more heavily, with the newest games counting several times as much as the oldest.
For evaluation I used a temporal holdout: train on 2012 through 2022, validate on 2023 through 2026, so the model is always judged on seasons it never saw. On that holdout it lands at a 0.139 Brier score and about 80 percent accuracy.
Calibration was the actual hard part
A model that is right 80 percent of the time is not the same as a model whose probabilities mean what they say. I cared about calibration because the whole platform is about probabilities, not just picks.
Plain isotonic regression, fit on a few hundred out-of-fold predictions, gave me calibrated probabilities that were also useless in a specific way: it collapsed distinct matchups into a handful of identical values, because isotonic produces a coarse step function. Most games came out at one of a dozen probabilities. The fix was to smooth the calibrator by interpolating linearly between the midpoints of its steps, which preserved the calibration mapping while restoring a continuous, unique probability for every game. That single change took the number of distinct predictions from a handful to essentially all of them.
There is a second, separate adjustment in the live serving path: after watching the deployed model be overconfident on real games, I compress the most confident predictions toward the middle. A model that says 85 percent when it is right 68 percent of the time is not honest, and the recalibration narrows that gap.
The feature I had to delete
At one point I added a head-to-head feature: how the two teams had done against each other earlier in the season. The validation numbers got suspiciously good, a 0.042 Brier score and over 90 percent accuracy. That is not a better model, that is leakage. Conference-tournament games are usually rematches of regular-season games, so a season head-to-head record nearly tells you the answer directly. I cut the feature from training entirely and kept it only for the human-readable explanations the agent can give. The discipline that matters in modeling is being suspicious of your best results, not just your worst ones.
Grounding the agent
The conversational agent runs on Claude with seven tools: look up a team, get a matchup prediction, get conference information, list top teams, get today's scores, find upset candidates, and build a full bracket. The crucial design point is what the agent is not allowed to do. Its matchup tool calls the same predict_matchup function as the rest of the platform, and the system prompt's first and strongest rule is that it must state the exact probability the tool returns and never invent, round away, or flip it. Seeds, records, and stats may only come from tool output. If the tools cannot answer something, the agent says so rather than confabulating.
So the division of labor is clean: the model decides, the agent narrates. The agent is not a smarter predictor sitting on top of the model; it is a careful spokesperson for it. It can only quote the number the tool returns, because that limit lives in the wiring, not in a prompt asking it to behave.
Keeping myself honest about accuracy
The platform locks each prediction before tipoff and never edits it afterward, which is the only way an accuracy tracker means anything. Games where the model is under 55 percent confident are labeled tossups and excluded from the accuracy numbers, so a coin flip that happens to land does not get counted as a correct call.
The narrative hook of the whole project is a bug I am glad I found. For a while, the sophisticated ensemble was not actually being used. The table that was supposed to hold the trained model's artifacts was empty, so every live prediction silently fell through to a simpler Elo-based fallback. Everything looked fine; the numbers were just quietly worse than they should have been. Fixing it meant building the missing pipeline end to end: export the trained artifacts, upload them, load and cache them at serving time, and verify the live path was using them. It is a good reminder that "the code runs and returns plausible output" is not the same as "the system is doing what you think it is."
What I would do differently
The hyperparameter tuning was ad hoc; the current model's settings are hardcoded from earlier experiments rather than produced by a tracked search, and I would set up a reproducible study so the choices are auditable. I would also add an automated regression on live accuracy, so a future change that quietly degrades calibration shows up as a failing check rather than a worse season. The model is in good shape. The scaffolding around proving it stays in good shape is the next pass.