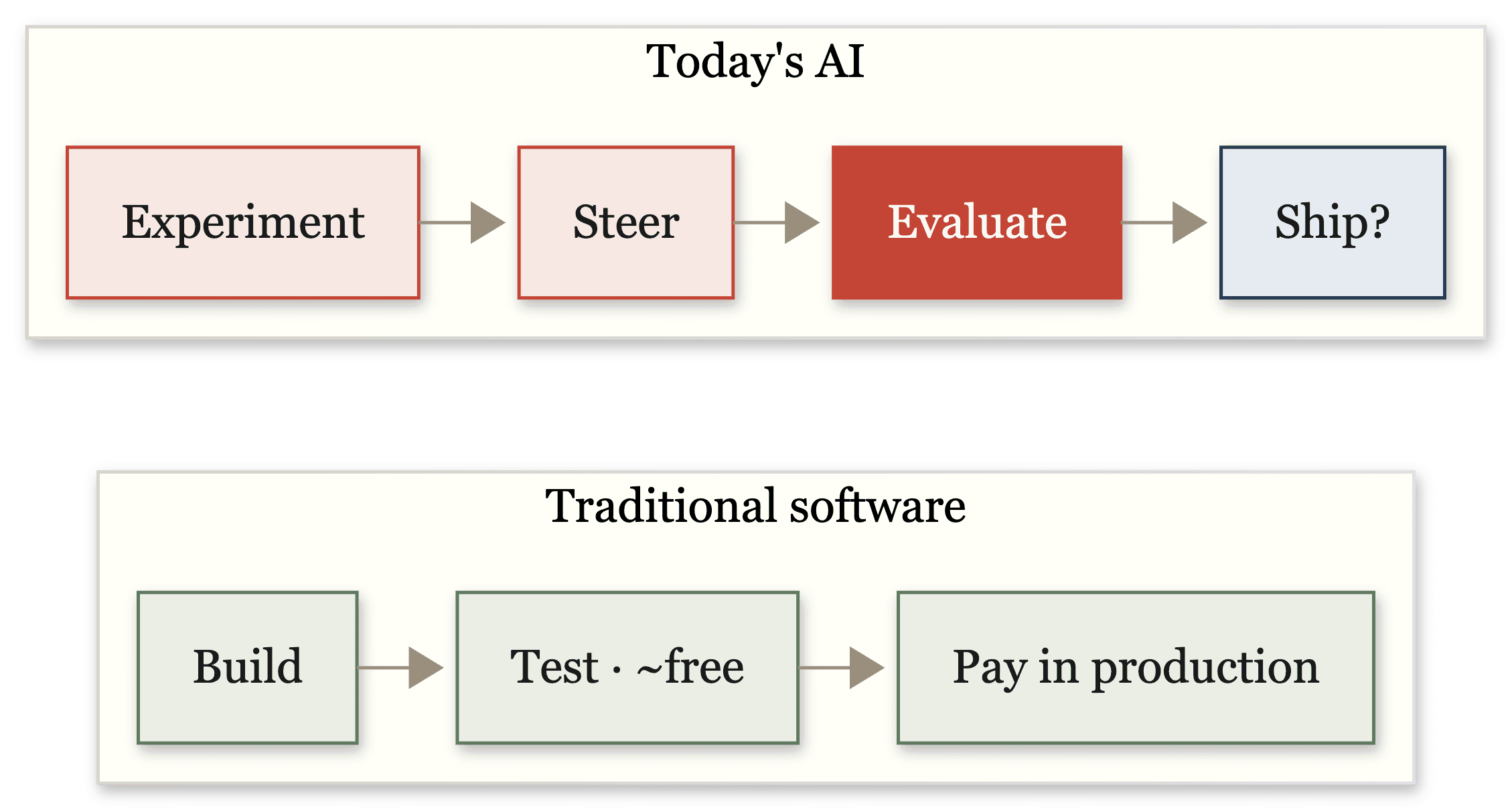
For most of software's history the cost curve had a familiar shape. Building was relatively cheap, testing was nearly free because it ran on a computer you already owned, and the real money started at production, when traffic arrived and you paid to run the thing at scale.
Today's AI inverts that. The expensive work has moved to the front of the timeline: the experimenting, the steering, the evaluating, all of which happens before anything reaches a user, and much of which never reaches one at all. Gartner expects at least 30% of generative-AI projects to be abandoned after proof of concept. An MIT NANDA study put it more starkly, finding 95% of enterprise GenAI pilots with no measurable impact on profit and loss. Those are not stories about weak models. They are stories about cost landing in places teams never budgeted for.
I have run into this directly building with AI, most recently on Mkopo, an agentic loan-origination system where I measured every dollar. What follows is where the money actually goes, in the categories I'd use to find a team's spend.
The experimentation tax
A demo is cheap. A working system is not, and the gap between the two is where most of the spend disappears. By several counts more than 80% of AI projects never reach production, roughly twice the failure rate of conventional software. The reason is rarely the part you can show in a demo. It is the last stretch: the reliability, the edge cases, the unglamorous integration. One cost analysis of the pattern put it well, that "the last 10% to 20% is where the real complexity hides."
What makes this tax easy to underpay is that experimentation feels like progress while it is quietly the most expensive phase. You are paying, in time and tokens and salaries, to answer a question deterministic software answered for free: will this work reliably enough to ship? Sometimes the answer is no, and you only learn it after you have spent.
The steering tax
There is a comfortable idea that AI lets less-experienced people do more. In practice it is closer to the reverse. Getting an agent to do useful work efficiently takes more fundamentals, not fewer. You have to know what good looks like to catch the model when it drifts, and you have to direct it deliberately. A vague instruction does not fail loudly. It wanders, and every wandering turn is a billed round-trip.
That skill gap is a real cost, just a hidden one. An engineer who can specify a task precisely and correct an agent in one pass runs a cheap loop. An engineer who cannot burns tokens and hours in trial and error, and often ships something worse. The expertise did not disappear when the typing got automated. It moved to directing the thing that types, and teams without it pay the difference in waste.
The legacy tax
Most companies are not building on a clean slate. They are building on systems that were never meant for AI: fragmented data, undocumented schemas, interfaces that assume a person in the loop. There are two ways through, and both cost money.
Point AI at the legacy system as it stands and it inherits the mess. Bad data goes in, unreliable output comes out, and you get an assistant nobody trusts. Gartner attributes 85% of AI project failures to poor or unready data, and warns that agentic systems strain older stacks hardest because they expect to act rather than just answer. The alternative is to build an integration layer whose only job is to make the old system legible to AI, which is a second project hiding inside the first. "Just add AI" usually turns out to mean a substantial engineering bill, and bolting capability onto an unready foundation rarely delivers the value it promised.
The evaluation tax
This is the cost I think is most underappreciated, and my own numbers show why.
Traditional unit testing is cheap because it is deterministic. You assert that a function returns 4, it returns 4, and the test passes for free on hardware you already own. You never had to buy a service to run a unit suite. A laptop or a CI runner was the whole bill.
An AI product does not get to stop there. You still write the ordinary unit tests, because most of the system is still ordinary software: the API, the database layer, the rules engine, the plumbing around the model. Those run for free, the same as always. But the part that makes it an AI product, the agent's behavior, cannot be unit-tested that way. Its output is not a fixed value you can assert against. It is a different sentence every time. So you add a second layer of testing on top of the first, and that second layer is where the new cost lives.
That layer is evaluation, usually some form of LLM-as-judge, where one model grades another's output. It changes the economics twice over. You are now paying for two test suites instead of one: the deterministic unit tests that cost only compute, and the eval suite that costs compute and tokens. And the eval suite is the expensive one, because a model good enough to judge nuanced output is a reasoning-grade model, the costly tier, and you run it constantly. Non-deterministic output means you are never quite finished, with a long tail of "better, but now this regressed" that deterministic software does not have.
Mkopo shows the split cleanly. It has 286 unit tests that run free in CI, like any codebase. It also has a twelve-task evaluation suite that spends real money every time it runs, and on a full run the frontier model I used purely for judging was 14% of the calls and 70% of the spend. The unit tests check that the software works. The evals check that the AI behaves, and only the second one lands on the Anthropic bill.
There is a final catch: the judges are not trustworthy out of the box. The research on LLM-as-judge documents consistent bias and instability, including verbosity bias, position bias, and self-preference, with no standard way to compare one judge against another, so you also spend effort validating the validator. The contrast is stark, and easy to underbudget: testing used to need a computer, and now it needs a computer plus a metered token bill on every run.
The bill moved left
Put those together and the shift is the whole point. The old model was cheap to build and test, and you paid at runtime when users arrived. The new model is expensive to build, more expensive to evaluate, and a large share of the spend happens before anyone benefits, on projects that often do not ship.
Production does not reset the meter either. Traditional software has near-zero marginal cost per request once it is running. AI carries a per-token cost on every inference, so going live is less the moment the meter starts than the moment it changes shape. It never really switches off. It moves from your experimentation budget to your inference budget.
The organizational tax
The technical costs are only half of it, and the other half is why budgets keep breaking. A 2025 survey of finance leaders found 85% of organizations misestimate their AI costs by more than 10%, and about a quarter are off by 50% or more, with that spend visibly eroding gross margins.
Adaptation is a large part of it. MIT traced most pilot failures not to the models but to a learning gap, to organizations that had not worked out how to use the tools, alongside the finding that internally built systems succeed about a third as often as tools teams adopt and learn well. People who use AI badly are a drag on every project they touch, and that training cost is real whether or not it shows up on a budget line. The opposite carries a cost too. Standing still while competitors compound their advantage is its own kind of spend, so plenty of teams are caught between expensive to adopt and expensive to ignore, paying on both sides.
What's next
The bottleneck is evaluation, and it is nowhere near solved. There is no framework you can drop in that judges arbitrary AI output reliably. Cheap models can check narrow, well-defined things, but anything needing real judgment needs a reasoning model, which is the expensive tier, so the cost of knowing whether your AI works tracks the cost of the AI itself. Research is moving on this, but until evaluation is both cheap and trustworthy the experimentation tax stays high and the gap between a pilot and production stays wide. That gap is the real story under the abandonment numbers.
None of this is an argument for waiting. The economics are punishing for teams that treat AI like ordinary software and meet the bill at the end. They are manageable for teams that build cost and evaluation in from the first week, the way you already track latency or error rates. On Mkopo every model call goes through one gateway that records its real cost to a table, so "what is this costing, and where" is a query, not a quarterly surprise. That one piece of plumbing changed which experiments I kept and which I cut, because I could see which ones were earning their spend.
The companies that pull ahead will not be the ones with the largest AI budgets. They will be the ones who can tell an experiment worth scaling from one worth stopping, before it becomes a multimillion-dollar proof of concept with nothing in production behind it. Most teams that are over budget today are not there because the models are bad. They are there because no one decided, going in, how they would know the difference.
Sources: Gartner on GenAI project abandonment · MIT NANDA "GenAI Divide," via Fortune · Gartner on AI-ready data · CIO on AI cost overruns · Survey of LLM-as-a-judge