"Constitutional AI" sounds like a research paper, and the original is one. In practice, in my loan-origination project, it's a loop you can read in a single file: a drafting model, a judging model, an explicit list of rules, and a hard cap on how many times they're allowed to argue. This is an account of that loop, what it does, what it caught, and the one time it failed to agree with itself and what the system did about that.
The loop
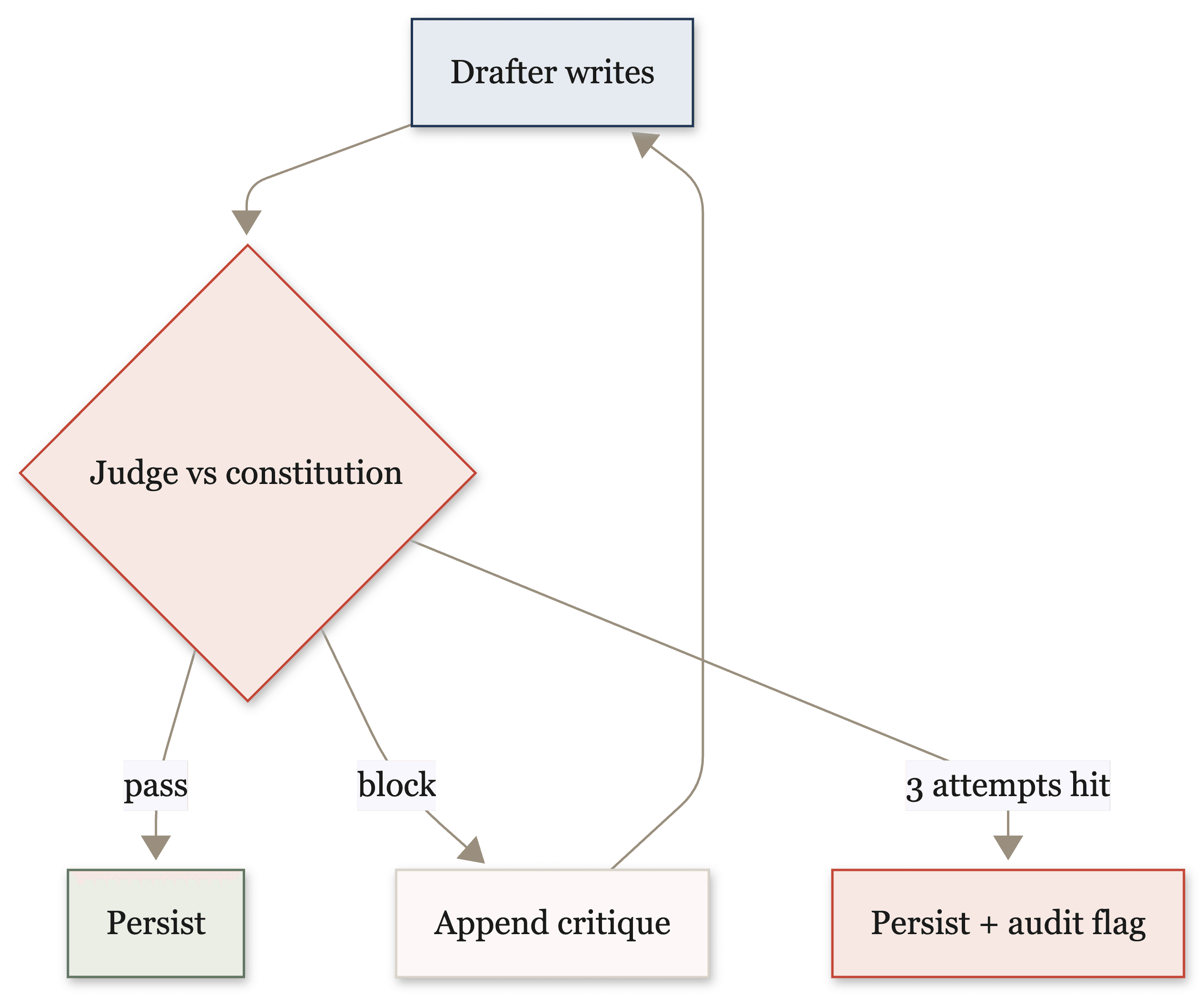
Two of the agents in the system draft text a human will eventually rely on, an underwriting summary and a decision letter. Both wrap their drafter in a judge. The drafter (Claude Sonnet) writes, a separate judge call (Claude Opus) scores the draft against an explicit constitution, and on a block-severity failure a LangGraph conditional edge sends the draft back to the writer with the judge's critique appended. The writer tries again with that feedback in hand. That is Self-Refine, the technique from Madaan et al., expressed as a graph edge rather than a prompt.
The part that makes it useful rather than decorative is the constitution. It isn't "be helpful and accurate." It's a written list of red lines specific to the task: no fabricated facts, nothing that contradicts the deterministic rules engine, no internal rule IDs leaked into text a borrower will read, the correct loan-class terminology. The judge scores against those, not against a vibe.
The cap is the whole point
Every account of agentic loops should start with where the loop stops, because the failure mode of "LLM critiques LLM" is an expensive infinite argument. Here the cap is three. After three block-severity rejections the loop terminates, persists the latest draft, and writes a guardrail_judgment audit event so a human reviewer sees an unresolved flag instead of either a silent retry that quietly gives up or a loop that never returns.
Why that matters: a judge that always passes is theater, and a judge with no cap is a runaway cost. A judge with a cap and a visible audit trail when it hits the cap is the only version that holds up. It catches what it can, and when it can't, it says so loudly, in a place a person will look.
What it actually did
On a reference run, the loop did real work rather than rubber-stamping:
- Across the decision agent's runs, every draft hit the judge. This isn't an optional path.
- More than half had at least one block-severity flag on the first attempt, which the Self-Refine retry then resolved.
- One underwriting draft (a hospitality loan, in the synthetic set) failed the judge three times in a row and maxed out the cap. It was persisted with the audit flag, unresolved, for a human to look at.
That last one is the result I'm proudest of, because it's the one most systems hide. The draft didn't get silently shipped. The loop didn't spin forever. The failure became a visible, queryable event. Every guardrail_judgment lands in the run's payload and surfaces on the observability page.
The cost, named
The judge isn't free. On that one tricky loan the guardrail loop added roughly $0.25 of LLM spend, extra Opus calls (the most expensive model in the system) spent specifically on catching problems. Across the whole pipeline, the frontier model I reserve for judging is 14% of the calls and 70% of the cost.
If you're tempted to cut it to save the quarter, here's the trade as I see it. The same run had the judge catch fabricated rationale in drafts that would otherwise have shipped. The cost of keeping the judge is measured in dollars. The cost of removing it is measured in the hallucination that reaches a borrower's adverse-action letter. For this domain, that's not close.
When to reach for this, and when not
A constitutional judge earns its cost when three things are true: the output is high-stakes, "wrong" is concrete enough to write down as rules, and a human can't review every single output by hand. Loan letters fit. A lot of things don't. If your output is low-stakes, or "good" is too fuzzy to enumerate, or your volume is low enough to review manually, a judge is over-engineering, and you'd do better spending the budget on a tighter drafter prompt and a smaller eval set.
What generalizes from this isn't "add an LLM judge." It's the shape: make the constraint explicit, bound the loop, and make the failure visible. A judge that can't be audited when it gives up is just a more expensive way to be wrong.