Mkopo (Swahili for "credit") is a loan-origination system I built to work through one question: how do you put LLM agents inside a regulated, high-stakes workflow without ever letting them make the call that matters? It runs on synthetic data and is not a deployed lending product. The engineering is real, though, and every number in it is measured and reproducible from the repo.
The one rule: the model drafts, the rules decide
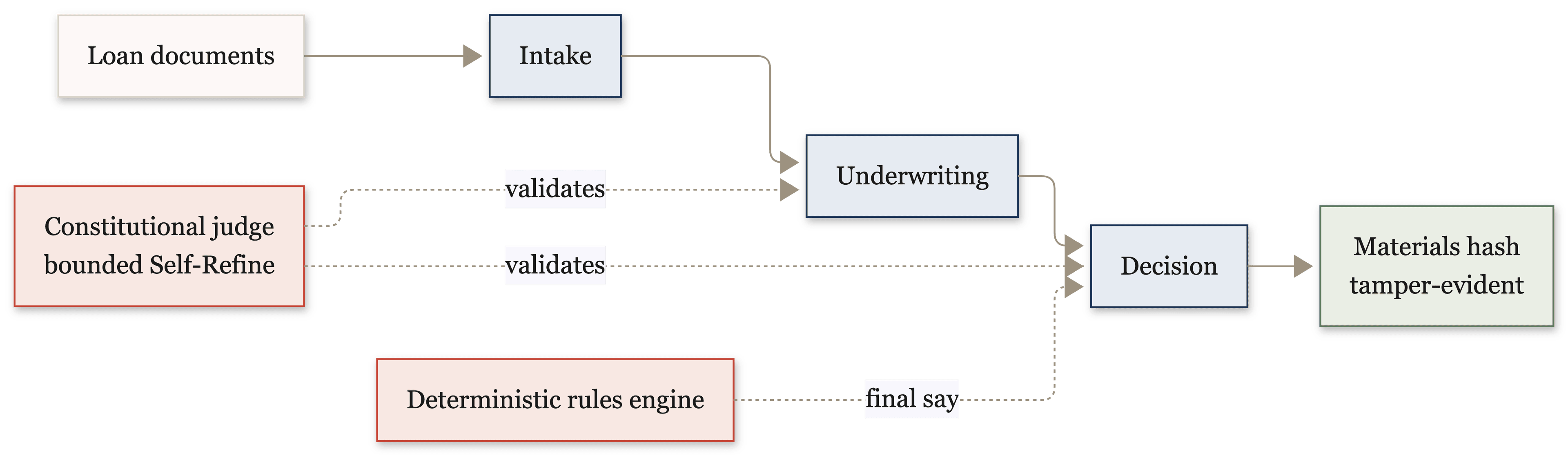
The load-bearing decision in the whole system is a separation of powers. A deterministic Python rules engine, not the LLM, has the final say on every credit decision. It computes the hard ratios a lender actually underwrites on (debt-service coverage, loan-to-value, debt yield, guarantor concentration for business loans; DTI and a FICO floor for personal ones) and returns pass or fail. The language model does the interpretive work around that: reading documents, drafting a cited summary, writing the borrower-facing letter. When the model's recommended verdict and the rules engine disagree, the rules win. The decision agent overwrites the model's choice to "decline" before anything is persisted, and writes a decision_override_to_decline audit event so the override is visible.
This is the principle I keep returning to across every AI system I build. A governance constraint enforced by a prompt is theater, because the model will not always obey it. The constraint has to be structural. Here the LLM is never the thing that decides. It is the thing that drafts, and a rules engine a regulator could read does the deciding.
Three agents, one forward-only pipeline
The work moves through three LangGraph agents, intake then underwriting then decision, over a loan state machine that only moves forward or terminates.
Intake reads the uploaded PDFs and extracts the fields that matter (borrower entity, income, credit score, loan amount, appraised value), confidence-scoring each one. Anything below threshold goes to a human review queue instead of flowing downstream silently. It identifies missing required documents, drafts a borrower-facing request email, then stops at an interrupt for underwriter approval, a human-in-the-loop gate the agent cannot cross on its own.
Underwriting runs the rules engine independently and has the model draft a summary whose every claim cites the extraction field it came from. Those citations are clickable in the UI, so a reviewer can jump from a sentence in the summary straight to the exact quote in the source document.
Decision re-runs the rules engine, so the two stages can never quietly diverge, then has the model pick a path: approve and draft a term sheet, conditionally approve with a list of conditions, or decline and draft an adverse-action letter, all subject to the override above.
Catching the model when it makes things up
Both drafting agents wrap their output in a constitutional judge, a separate LLM call that scores the draft against an explicit, written constitution: no fabricated facts, nothing that contradicts the rules engine, no rule IDs leaked into text a borrower will read. On a block-severity failure, a LangGraph conditional edge sends the draft back to the writer with the judge's critique attached. That is Self-Refine as a workflow, and it is bounded. After three attempts the latest draft is persisted with a guardrail_judgment flag, so a human sees the unresolved problem instead of the system shipping it or looping forever.
On the reference run this did real work rather than rubber-stamping. One underwriting draft hit the cap, failing the judge three times in a row, and was persisted flagged for review. That is the visible-failure behavior I wanted, instead of a silent retry that eventually gives up.
Decisions you cannot quietly change
Every decision is stamped with a SHA-256 hash of the materials it was made on: the documents, the extractions, the parties. If any of those inputs change afterward, the hash no longer matches, the UI flags the drift, and forward transitions are blocked until the decision is re-run. A reviewer or a regulator can verify exactly what inputs produced a given decision, and post-hoc tampering shows up instead of passing unnoticed.
What it costs, measured
Every LLM call in the system goes through one gateway that records the real token counts, the computed cost, and the latency to a single llm_calls table, so the economics are a SQL query rather than a guess. End to end, a loan runs about eleven LLM calls, roughly $0.07, and about forty seconds. Across a full populate run the spend was $5.88, and the part that surprised me once I queried it was that Opus made up 14% of the calls but 70% of the cost, because the two places I use a frontier model are both judges. The structured-output schemas force a 21.7% retry rate when the model overruns a field bound, and every retry recovered, with zero structurally invalid responses reaching the database.
Scope
Mkopo is a portfolio project, not a lending product, and the scope reflects that. It runs on fabricated borrowers and documents. It has none of the compliance machinery a real lender needs: no credit-bureau integration, no HMDA or TRID handling, no OFAC screening, no SSO, no multi-tenancy, and the orchestrator runs inline rather than on a queue. What is real and working is the part I built it to demonstrate: the agent graphs, the deterministic rules engine, the constitutional judge with its bounded Self-Refine loop, the materials-hash integrity check, the input-layer injection detector, and an observability layer that makes every LLM call, agent step, and audit event queryable. It is covered by 286 tests and a CI gate that runs a twelve-task evaluation suite on every push. The point of it is to show how I would engineer the safety and auditability of an agentic financial workflow.